
티스토리 뷰
DenseNet: Densely Connected Convolutional Networks (CVPR 2017)
song 2024. 3. 29. 14:19논문: https://arxiv.org/abs/1608.06993
Shortcut connection을 활용한 연구로 CVPR2017에서 best paper로 선정된 논문이다.
0. Abstract

최근에 ResNet 등의 연구를 통해 shortcut layer를 통해 모델을 더 깊고 정확하게 만들 수 있다는 것을 알게됐다. 본 논문에서는 모든 layer를 연결하는(L개의 layer 있다면 마지막 transition layer까지 L+1개의 layer를 모두 이어 L(L+1)/2 개의 connection을 생성) dense network 구조를 제안한다. 이런 구조를 통해 아래 세 가지 advantage를 얻을 수 있다.
- Vanishing gradient problem 완화
- Feature propagation 강화
- Feature 재사용을 통한 parameter 감소
DenseNet은 CIFAR-10, CIFAT-100, SVHN, ImageNet 4개의 dataset 대부분에서 SOTA 가볍고 좋은 성능을 냈다.
1. Introduction

Depth가 깊어짐에 따라 발생하는 gradient가 소실 문제를 해결하기 위해 resnet의 identity connection을 포함한 많은 연구들이 진행되었다. 네트워크 구조, 학습 방법 등에 따라 다양한 접근방법이 있지만 이들 모두는 layer간 short path를 생성한다는 공통점이 있다.


우리는 이런 shortcut에 대한 insight를 간단한 연결로 정제하여 제안한다. Information flow를 최대화하기 위해 같은 feature map size를 같은 layer끼리 모든 layer를 연결 한다. 기존의 feed forward 방법처럼 한 방향으로 흐르는 기조는 유지하되, input이 앞의 모든 layer이고 out은 뒤의 모든 layer의 input으로 쓰이게 하였다. input을 합칠 때는 element-wise summation인 ResNet과 다르게 feature map을 channel level로 concat하였다.

많아진 connection과 반대로 parameter는 오히려 줄었다. 이는 feature map에 대한 학습을 중복으로 할 필요가 없기 때문이다. 예를 들어 전통적인 conv net에서 feature map 10개가 어떤 layer를 통과한다고 하면 이 layer는 새로운 특성을 추가하면서도 input으로 들어온 10개의 feature map의 특성도 보존해야한다. 그래야 다음 layer로 전달할 때 지금까지 얻어낸 정보를 잃지 않으면서 추가된 정보와 함께 전달할 수 있기 때문이다. 그 이후의 layer에서도 계속해서 더해진 정보를 보존해야하는데 필연적으로 feature map의 수가 많아지게 된다. 이렇게 늘어난 feature map은 학습해야할 weight가 늘어나야한다는 것을 의미하고, 이는 추가된 정보(특정 layer의 feature map)를 보존하기 위해 이 이후의 layer에서도 계속해서 weight를 사용해야한다는 의미가 된다.


ResNet의 경우 정보의 보존을 위해 identity connection을 사용한다. 이는 shortcut 사이의 layer는 input 정보를 보존할 필요가 없기 때문에 효율적이지만, 구조적으로 유사한 RNN과 비교했을 때 훨씬 많은 parameter를 갖고 있다. t에 상관 없이 하나의 weight (그림에서 K)만 들고 있는 RNN과 달리 ResNet은 모든 K를 다르게 갖고 있기 때문이다.

DenseNet은 다르다. 모든 connection이 있기 때문에 각 layer가 정보를 보존할 필요가 없이 새로운 정보를 뽑기 위한 기능만 하면 된다. 그에 따라 filter의 수는 적어지게되고, 각 layer에서 뽑힌 새로운 정보는 direct connection으로 한데 모여 정보 보존+추가 정보 모두 담은 collective knowledge가 된다. 즉, 정보의 보존은 모든 connection을 연결함으로써 따로 보존을 위한 학습이 필요없게하고 layer에서는 적은 filter로 새로운 정보만 추출하면 되도록 구조를 변경한 것이다.

Parameter efficiency와 더불어 이런 dense connection은 output(loss) 계산에 직접적으로 관여하게 되기 때문에 gradient, information flow를 원활하게 만들어 학습에도 도움이 된다. 뿐만 아니라 regularization 효과도 있는 것을 보였다.
2. Related Work

Depth를 늘린 ResNet, Width를 늘린 Inception net과 달리 DenseNet은 feature의 재사용을 활용하는 밀도 있는 구조를 만들려고 했다.
3. DenseNets

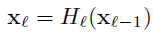
전통적인 conv net에서 transformation은 위와 같다. H는 단순히 layer 하나라기보다 NB, ReLU, Conv 등을 포함한 l번째 layer block이다.
ResNets

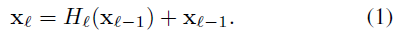
Short cut으로 information이 바로 전달되지만 summation으로 합쳐지기 때문에 정보 흐름을 방해할 수 있다.

Dense connectivity
정보흐름을 더 원활하게 하기 위해서 모든 layer의 direct connection을 만들었다. 이전 layer의 output인 feature map들을 concat하여 input을 생성한다.
Composite function
앞서 말한대로 H는 단순히 layer 하나가 아니고 Batch normalization, ReLU, 3x3 convolution layer를 합쳐 놓은 composit function이다.
Pooling layers


feature map의 concat은 feature map size가 같아야만 가능하다. 하지만 conv net에서 down sampling으로 feature map을 줄여나가는 과정은 필수이다. 이를 위해 전체 network를 3~4개의 dense block으로 나누었다. dense block 내부는 여러개의 H로 구성되어 있고 이는 모두 같은 크기의 feature map을 생성한다. dense block 내부의 layer(H)는 모두 연결되어 있다.
이 dense block 간의 연결을 trasition layers라고 부르며 convolution과 pooling을 한다. transition의 cov는 BN + 1x1 Cov로 구성하며 pooling은 2x2 avg pooling을 한다.
Growth rate (k)

composit function H의 output feature map 크기 k를 말한다. l번째 H는 input 채널 수+(l-1)k 개의 채널을 input으로 받는다. 다른 network와 달리 k=12 처럼 작은 수로도 준수한 성능을 낸다. Dense block 안에서는 layer를 지날 때마다 k 개씩 추가되는 feature map의 집합("collective knowledge")을 모든 layer에서 접근할 수 있기 때문에 global state로 생각할 수 있다. 각 layer에서 정보의 보존을 위해서 feature map 수가 많은 다른 전통의 conv net과 달리, 각 layer의 output이 어디에서나 접근 가능하기 때문에 layer propagation에서 기존의 정보를 복제할(유지할) 필요가 없다.
Bottlenect layers

k개의 output만 낸다하더라도 dense block의 후반 layer는 k(l - 1)개의 input을 처리해야하기 때문에 계산량이 많아질 수 있다. 이를 해결하기 위해 1x1 cov layer를 앞에 두어 channel 수를 줄이는 bottleneck 기법을 도입한다. 결과적으로 H가 BN-ReLU-3x3Conv에서 BN-ReLU-1x1Conv-BN-ReLU-3x3Conv로 변경된다. 이렇게 변경된 H가 적용된 모델을 DenseNet-B(Bottleneck)이라고 칭한다. 1x1Conv는 4k개의 feature map을 생성한다. 즉, H를 통과할때 k(l-1) -> 4k -> k 로 채널 수가 변경된다.
Compression

Dense block을 잇는 transition layer에서 feature map의 수를 줄여 parameter를 줄이는 방법이다. 0~1 사이의 compression factor를 두어 이를 곱한 값으로 feqture map의 수를 줄였다. 실험에서는 0.5로 두어 절반으로 줄이게 했다. DenseNet-B에 이것을 적용해서 DenseNet-BC(Compression)이라고 칭한다.
4. Experiments
4.1 Datasets
CIFAR

10/100 class, 32x32 size, 50k train(5k val), 10k test
CIFAR-10, CIFAR-100을 사용했고 random crop with 2 padding, horizental flip, mean-std normalization 등 CIFAR dataset에 많이 쓰이는 augmentation을 적용했다. augmentation을 적용한 dataset을 C10, C100, 적용한 dataset을 C10+, C100+으로 표기한다.
SVHN

10 class(digit), 32x32 size, 73k(6k val) train (+511k easier), 26k test
augmentation는 따로 하지 않고 pixel을 255로 나눠 [0, 1] range로 변경하는 작업만 했다.
ImageNet

1000 class, variant size, 1.2m train, 50k val
짧은 면을 [256, 480] range random으로 resize하고 (+random horizental flip) 224x224 random crop. pixel은 -mean으로 normalization, PCA 통한 color agmentation. test할 때는 1crop, 10crop 둘 다 결과를 측정함
4.2 Training

이런저런 training detail있고, Augmentation 없는 dataset(C10, C100, SVHN)에서는 각 composite layer 마지막(3x3 conv)에 0.2 dropout 추가했다.
4.3 Classification Results in CIFAR, SVHN
Accuracy
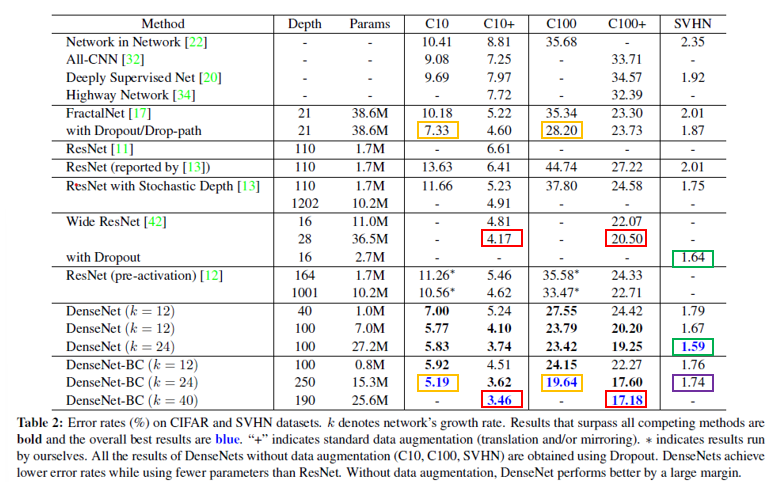
DenseNet-BC는 모든 CIFAR dataset에서 overall best(주황, 빨강)였으며 augmentation이 없는 C10, C100에서 30%나 정확도가 향상(초록)했다. SVHN dataset에서도 DenseNet (k=24)가 best였지만 BC에서 성능이 떨어진 것은 간단한 dataset으로 인한 overfit이라고 한다(보라).
Capacity

Model의 capacity(k, L)이 거짐에 따라 representational power가 증가함을 보였다. ResNet-1202 (19.4M params)가 보였던 것과 달리 overfitting이나 optimization difficulty가 없다는 걸 보여준다.
Parameter Efficiency

DenseNet-BC가 파라미터 수가 비슷한 FractalNet, Wide ResNet 보다 성능이 좋았고(빨강), ResNet 대비 90%나 적게 parameter를 사용했음에도 성능이 더 좋았다(주황).
Overfitting
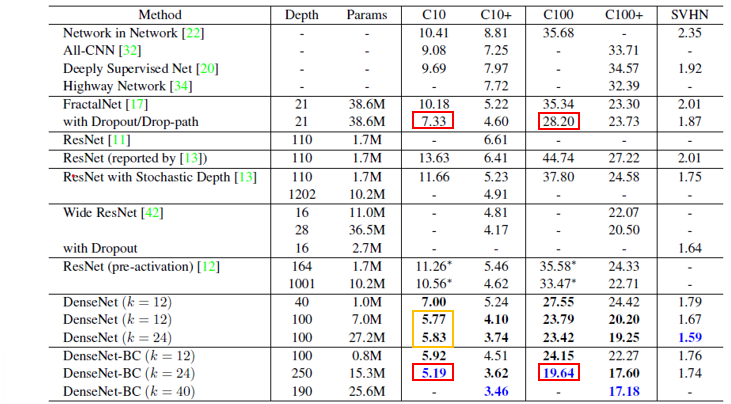
parameter의 효율적인 사용은 overfitting을 완화하는 데도 좋은 경향을 보였다. Augmentation 없는 dataset에서 성능이 SOTA보다 좋았고(즉 일반화 능력이 좋았다)(빨강), Normal DenseNet에서 overfit의 경향이 약간 보였으나 BC를 활용해 극복할 수 있다.
4.4 Classification Results in ImageNet

ImageNet dataset에서도 layer에 따라 성능 향상이 있었다.
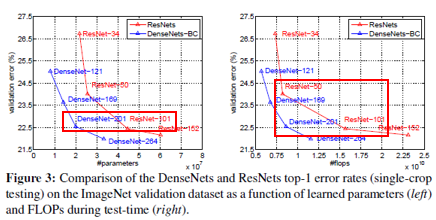
ResNet과 비교했을 때 훨씬 적은 parameter를 사용하면서도 비슷한 성능을 냈다(왼쪽). ResNet-50이랑 비슷한 계산량을 같는 DenseNet-201은 ResNet-101과 유사한 성능을 보였다.
(*공정한 비교를 위해 모델을 제외한 모든 세팅을 ResNet과 동일하게 했다. 즉, hyperparameter를 DenseNet에 맞게 튜닝하면 더 좋을 것이다.)
5. Discussion
Model compactness
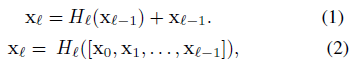

ResNet의 summation과 DenseNet의 concat은 유사해보이는 구조이지만 이 차이는 상당히 다른 양상을 보인다.

summation하지 않고 단순히 concat을 하기 때문에 후위의 layer들은 앞의 feature map을 재사용할 수 있게 되고 이는 model을 compact하게 만든다. 왼쪽과 중간의 두 표는 parameter efficiency를 비교하기 위한 표이다. 왼쪽은 DenseNet의 variation에 따른 결과이고, 중간에는 유명한 network 중 가장 parameter efficient한 pre-activation ResNet과 DenseNet-BC(k=12)를 비교했다. DenseNet-BC가 모든 variation 중 parameter efficient했고, ResNet에 비해 3배정도 parameter efficient 했다. 오른쪽 표에서 겨우 0.8M parameter만 사용한 DenseNet-BC-100이 10.2M ResNet-1001 과 비슷한 성능을 내는 것을 확인했다.
Implicit Deep Supervision

DenseNet의 accuracy는 shortcut을 통한 loss의 supervision(감독) 덕분이라고 할 수 있다. Deeply-supervised net(DSN)이라는 연구에서 hidden layer에 classifier를 달아 중간 layer가 더 특성을 반영할 수 있도록 했는데, DenseNet에서는 direct connection을 통해 loss에 직접(가까이) 관여하게 하여 classifier를 단 것과 유사한 효과를 낸다. 하지만 실제로 classifier를 단것이 아니라 loss는 하나만 구하는 것은 마찬가지이고 이는 DSN에 비해 훨씬 덜 복잡한 구조이다.
Feature Reuse
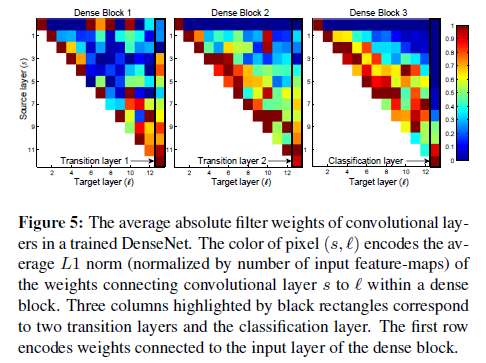

DenseNet에서 이전 layer의 output이 얼마나 활용되는지 확인하기 위한 실험을 했다. 어떤 layer s가 있을 때, s의 input을 구성하는 0~s-1 layer를 source layer라 하고, source layer 각각이 layer s에서 어느정도의 weight를 차지하는지 확인하는 실험이다(각 feature map에 할당된 weight의 절대값 평균으로 측정).

- column을 보면 각 s들이 골고루 반영된 것을 볼 수 있다. 즉, direct connection으로 앞쪽의 feature들도 잘 사용이 되었다.
- 제일 오른쪽 column(transition layer)도 s들이 골고루 반영되어있다. 즉, transition layer 역시 많은 부분 direct connection으로 영향을 받았다.
- Dense block 2,3 은 앞의 transition layer의 output에는 weight을 거의 할당하지 않는다. 이 putput을 계속 사용하지 않는 다는 것은 이 후의 layer에서 추출하는 feature들의 정보를 중복으로 담고 있기 때문이다. DenseNet-BC가 이걸 반으로 줄여도 성능이 좋다는 것이 반증이다.
- Final layer는 뒷쪽에서 뽑힌 feature에 많은 가중치를 둔다. 즉, high level feature는 나중에 뽑힌다.
6. Conclusion

모든 connection을 연결하는 DenseNet을 제안했고 다음과 같은 결과를 얻었다.
- Parameter 증가(k, L)에 따라 overfit, degradation 문제 없이 accuracy 향상된다.
- SOTA에 비해 적은 parameter를 사용하고 computation이 적다.
- ResNet의 hyperparam을 그대로 써서 실험했기때문에 DenseNet에 맞게 tuning하면 더 좋을 것이다.
간단한 connectivity rule을 적용함으로써 Identity mapping(shortcut), Deep supervision(loss에 직접 관여), Deversified depth(shortcut을 통해 depth가 다양해짐)의 특성들을 통합했고 이는 feature reuse를 가능하게 하여 모델을 더욱 compact하고 accuracy하게 만들었다. 이러한 compact 구조는 feature를 내포하게 만들고 중복을 줄이면서 DenseNet을 좋은 모델로 만든다.
'Deep Learning Papers' 카테고리의 다른 글
| Score-Based Generative Modeling Through Stochastic Differential Equations (2) | 2024.05.01 |
|---|---|
| DDPM: Denoising Diffusion Probabilistic Models (0) | 2024.04.15 |
| ViT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scal (0) | 2024.04.09 |
| Transformer: Attention Is All You Need (NIPS 2017) (0) | 2024.04.02 |
| ResNet: Deep Residual Learning for Image Recognition (CVPR 2016) (1) | 2024.03.22 |